EHC ❯ Concurrency issue: element is missing on cache, but reappears later
-
Bug
-
Status: Open
-
2 Major
-
Resolution:
-
ehcache-core
-
-
isobolev
-
Reporter: isobolev
-
September 21, 2012
-
0
-
Watchers: 4
-
November 02, 2012
-
Attachments
{kind=link}
Description
We use EhCache in highly concurrent application(basically ETL) to cache data with overflow to disk when too large files are processed.
Elements have unique IDs, which grow and only processsed(pushed to cache, then retrieved once). Recently we’ve spotted a case, where one processing stage was putting an element, while another one were reporting it is missing.
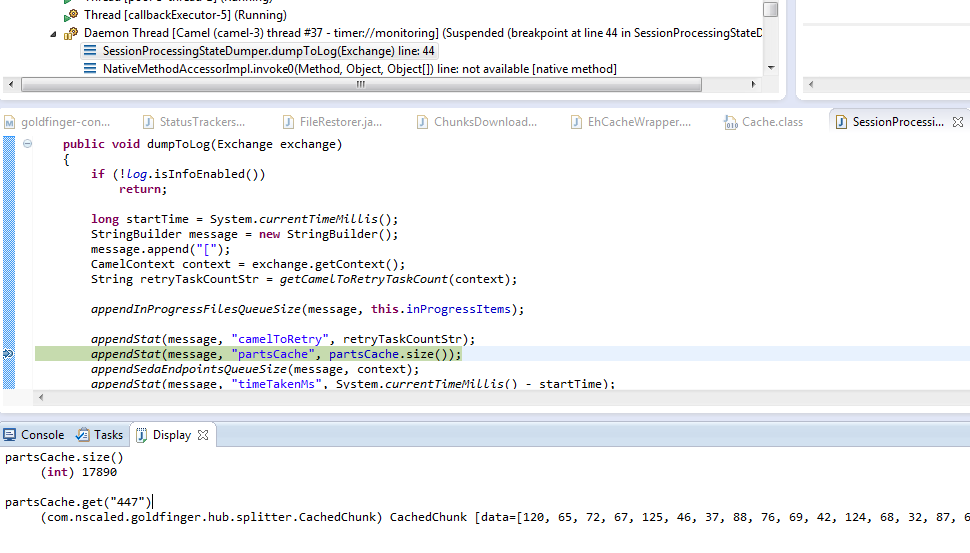
Later on, when I connected with a debugger to the same process I was able to see element returned by cache(pls see the attachment).
Knowing that items are up to 64k in size and that #448 is failed, I assume we haven’t overflowed the cache.
____________________________________________ 11:14:46.325 [Camel (camel-1) thread #12 - seda://chunksToDlBatched] TRACE c.x.y.Splitter - Putting to com.xxx.yyy.partsCache: 447 11:14:46.325 [Camel (camel-1) thread #12 - seda://chunksToDlBatched] DEBUG net.sf.ehcache.store.disk.Segment - put added 65792 on heap . . . 11:16:37.636 [Camel (camel-1) thread #16 - seda://writeToTarget] ERROR c.x.y.Writer - Internal error, part #448 is missing
_____________________________________________ [root@122dev1]# ls -la /tmp/ehcache_root/ total 1155664 drwxr-xr-x 2 root root 4096 Sep 21 11:12 . drwxrwxrwt 5 root root 4096 Sep 21 11:12 .. -rw-r–r– 1 root root 1182226369 Sep 21 11:16 com.xxx.yyy.partsCache.data
Pls find ehcache log and configuration attached and advice on what could actually be done here from our side.
Comments
Ivan Sobolev 2012-09-21
Ivan Sobolev 2012-09-21
Also with regards to stuff quoted in description, this is more relevant:
11:14:46.325 [Camel (camel-1) thread #12 - seda://chunksToDlBatched] TRACE c.x.y.Splitter - Putting to com.xxx.yyy.partsCache: 448 11:14:46.325 [Camel (camel-1) thread #12 - seda://restore.chunksToDlBatched] DEBUG net.sf.ehcache.store.disk.Segment - put added 65792 on heap
Ivan Sobolev 2012-09-24
A test case proving the issue.
Ivan Sobolev 2012-09-24
A workaround is to synchronize Cache#get and Cache#put methods usage externally.
This contradicts Cache#get method JavaDoc: ‘Synchronization is handled within the method.’
Ivan Sobolev 2012-09-24
A test case proving the issue.
Alexander Snaps 2012-10-01
I think the issue is related to OSS disk store (that stores the keyset in mem) and ARC pooling, which triggers the eviction you’re seeing. You could validate in your real app, I’ve added a
public void printStats() {
System.out.println(MemoryUnit.BYTES.toMegaBytes(getCache().calculateInMemorySize()));
System.out.println("Evictions: " + getCache().getStatistics().getEvictionCount());
}
method to the attached EhCacheWrapper and enabled stats, and do see eviction happening. I can’t validate the bug really given what I see there. I’m confused about the “reappears” later statement in the title though
Ivan Sobolev 2012-10-02
A log of bug being reproduced with metrics dump being added after put and get operations.
James House 2012-10-02
Alex, can you please continue to try to get to the bottom of this. thanks.
Ivan Sobolev 2012-10-02
Alex, pls see the log attached. Metrics said there were 3 evictions and a problem appeared long after last one of them happened
23:44:09.867 [pool-2-thread-6] INFO net.sf.ehcache.EhCacheWrapper - Get.evictions: 3
23:44:26.591 [pool-2-thread-8] INFO net.sf.ehcache.EhCacheWrapper - Get.evictions: 3
23:44:26.592 [pool-2-thread-8] ERROR net.sf.ehcache.EhCacheBugTest - 17832 was missing
I’m using https://jira.terracotta.org/jira/secure/attachment/17951/ehc-971-testcase.zip to validate this. It does not work for you?
Alexander Snaps 2012-10-02
Upon further investigation, I also think your test is racy… In the GetterAndRemover, you probably want to do a
key = existingKeys.remove(numToCheck);
right away in the first synchronized block… Only quickly looked at it, but I think the get and remove afterwards (in a further synchronized block) isn’t correct… Modifying the test as such, and also adding an eviction listener to record evicted keys, not having the test fail when such a key is missing, the test seems fine for me… Again though, can you elaborate on elements reappearing ?
Alexander Snaps 2012-10-02
There probably still are further races in this test though. When I sum cache size & evicted elements I seem to get a higher number than the test reports…
In cache: 34060, total elements seen 34061 (1 evicted)
19:22:43.390 [main] INFO net.sf.ehcache.EhCacheBugTest - Elements stored and tested: 34055 <= if I interpret this right that is...
Alexander Snaps 2012-10-04
Can you confirm the race in your code ? I can’t reproduce what you are seeing… If the test is indeed the issue, I’ll let you close this. Otherwise feel free to reassign to me with more details…
Ivan Sobolev 2012-10-04
*Unfortunately I can’t reassign it to you*
What do you mean by ‘test is indeed the issue’? - test reproduces the same thing I’m seeing in my app. The only thing is that app takes almost a day to crash with that kind of mystery, thus I prefere to use the test.
*Elements reappearing* - whas the case where my working app reported that an element is missing, than I’ve connected via debugger to it and requested the element(remember they are unique and added once) - cache reported element was there.
About the test being racy: * it starts to call ‘remove’ on elements when a cache size threshold is reached(targetCacheCapacityElements = 50000). For me test fails for me even on 2k element - long before removal will even kick off * Cache#remove() says ‘Synchronization is handled within the method’
Alexander Snaps 2012-10-05
Ivan, I can’t use the test to prove much as it is racy. I’ve modified it at such:
``` class GetterAndRemover implements Runnable { public void run() { while (keepRunning.get()) { String key; int size; int numToCheck; synchronized (Putter.class) { size = existingKeys.size(); if (size == 0) continue;
numToCheck = rand.nextInt(size);
key = existingKeys.remove(numToCheck); // makes sure we don't have 2 threads race on the same key
if (ChunksCacheWrapper.evicted.remove(key) != null) { // Ignores keys missing because of eviction triggered by the key set being held in men and impacting the maxBytesLocalHeap setting you've set
continue;
}
}
if (unit.get(key) == null)
{
log.error("{} was missing", key);
keepRunning.set(false);
problemFound.set(true);
}
if (size < targetCacheCapacityElements)
continue;
unit.remove(key);
}
} }```
The ChunksCacheWrapper.evicted is a ConcurrentHashMap that, using a listener, keeps track of all keys evicted. So fixing the race in the test and accounting for evicted keys, I can’t reproduce the issue (I ran it a couple of times for 10 minutes each run).
I hope the changes there make sense. So, could you please verify your usage and provide a test that reproduces the issue and doesn’t suffer any threading issues, and accounts for all factors at play ? I’m not saying there is no bug, but I can’t see anything at all as of now. Also note that the jira says the issue is in 2.5.2 and the attached example uses 2.6.0… I’ve tested both versions without being able to reproduce the issue.
Last but not least, I wonder whether even accounting for eviction you might not be able to suffer from this… iirc, there is no ordering guarantee wrt accessing the cache and listeners invocations.
Actually just a moment ago reproduced with 2.6.0